논문: CVPR 2016 Open Access Repository
code: zhoubolei/CAM: Class Activation Mapping
0. summary
- 이 연구에서는 Global Average Pooling(GAP) 레이어가 이미지-라벨 수준으로만 학습된 CNN이 뛰어난 지역화(localization) 능력을 갖게 하는 원리를 설명합니다.
- GAP는 이전에, 정규화 등 여러 다른 이점들을 위해 제안되었으나, 이는 generic localizable deep representation을 형성하며, 암시적(implicit)으로 CNN이 이미지에 주의(Attention)하는 영역을 드러내는 것을 발견했습니다.
- ILSVRC 2014 데이터셋의 object localization task에서 bbox annotation 없이 37.1%의 top-5 error를 달성했습니다.
- 네트워크가 단순히 분류(classification) 작업만을 위해서 학습되었음에도 불구하고 이미지 내에서 Discriminative region을 효과적으로 localization 할 수 있음을 입증했습니다.
1. Introduction
Object Detectors Emerge In Deep Scene CNNs 논문은 Scene recognition을 학습하는 과정에서 Object detector가 자동으로 생성됨을 보입니다. 그러나, 해당 논문은 Global Max Pooling과 FC layer를 사용했기 때문에, Object localization을 하기 위해선 FC 레이어는 무시해야 합니다. 저자들은 학습 단계서부터 FC 레이어를 제거하면서도 성능을 대부분 유지하며, 전체적인 네트워크를 이해하기 쉽게 새롭게 제안합니다.
NIN 및 GoogLeNet은 FC layer의 제거를 통해 모델의 파라미터 수를 줄이는 동시에 높은 성능을 유지하는 모습을 보입니다.
특히, NIN은 오버피팅을 방지하기 위해 GAP을 제안합니다.
저자들은 GAP가 오버피팅을 방지하는 역할 뿐 아니라, 네트워크가 마지막 계층까지 뛰어난 localization 능력을 유지하는 능력을 갖도록 함을 발견했다고 합니다.
GAP 자체는 저자들이 제안하는 novelty가 아니지만, 이를 통해 discriminative localization이 가능하다는 관찰은 기존 연구와 차별화 된다고 주장합니다.
2. Related Work
2.1 Network In Netowkrk
요약: NIN은 GAP를 처음 제안한 논문입니다.
Motivation: (1) CNN에서 FC 레이어 대신, GAP를 사용하면 feature map과 category가 직접적으로 연관지어지게 되면서 해석이 용이해집니다. (2) FC 레이어는 가중치가 매우 많기 때문에 Overfitting이 일어날 가능성이 높습니다. GAP는 이러한 문제를 해결해줍니다. (3) GAP는 공간 정보의 변형에 취약하지 않습니다. 그 예로, 강아지를 예측하는 CNN 모델은 이미지의 좌측 상단에 강아지가 있든, 우측 하단에 강아지가 있든 feature map 기반의 평균 값으로 분류를 수행합니다.
2.2 Object Detectors Emerge In Deep Scene CNNs
요약: 객체의 개념을 명시적으로 가르치지 않았음에도 불구하고, 장면 인식(Scene recognition)을 학습하는 과정에서 객체 감지기(Object detector)가 자동으로 생성되며, 하나의 네트워크가 Single forward pass로 장면 인식과 객체 지역화(object localization)을 모두 수행할 수 있음을 보입니다.
특징: GMP(Global Max Pooling)과 FC 레이어를 사용합니다. 따라서, 객체의 일부분만 감지하고 나머지는 무시합니다.
2.3 Self-Taught Object Localization with Deep Networks
요약: 객체가 포함된 영역을 마스킹하면 일반적으로 class prediction score가 크게 감소하는 아이디어를 통해 객체를 지역화 하는 방법을 제안합니다.
특징: 자가 학습 기법(self-taught method)을 통해 자동 생성된 바운딩 박스가 이미지-박스 데이터를 사용해 훈련된 객체 탐지기(object detector)와 유사한 수준의 인식 성능을 달성했습니다.
2.4 Weakly Supervised Object Localization with Multi-Fold Multiple Instance Learning
요약: Weakly supervised 기반 Object localization 에서는 잘못된 물체 위치로 bounding box가 수렴할 수 있습니다. 따라서, multi-fold로 나눠서 각 fold마다 object detector를 학습하여 잘못된 위치로 bounding box가 수렴하는 것을 보완해줍니다.
특징: 탐지기를 훈련하고, 훈련된 탐지기들을 바탕으로 객체 위치를 추론한 후, 추론된 위치를 다시 탐지기 훈련에 사용하는 반복적 학습 과정으로 이루어집니다. 즉, 전체 과정이 하나의 연결된 학습 과정(end-to-end)이 아닌 여러 번의 forwrad-pass가 필요합니다.
그러나, 2.3 ~ 2.4 의 접근 방법은 weakly-supervised 방법 기반으로, 객체 지역화에 있어서 유망한 결과를 보였지만, end-to-end로 학습되지 않으며, 객체를 지역화하기 위해 네트워크를 여러 번 forward-pass 해야 하는 단점이 있습니다. 따라서 실제 대규모 데이터셋에 적용하기 어렵습니다.
또한, 2.2 의 접근 방법은 전체 아키텍처 중 합성곱 계층만 분석하고, fc layer는 무시했기 때문에 전체적인 그림을 불완전하게 제시했다고 본 논문에서 지적하고 있습니다.
3. Method
이 논문은 CNN에서 GAP를 사용하여 Class Activation Map(CAM)을 생성하는 절차를 설명합니다. 특정 카테고리에 대한 CAM은 CNN이 해당 카테고리를 식별할 때 사용하는 판별적 이미지 영역을 나타냅니다. 즉, 강아지 이미지를 강아지라고 판별하기 위해서 이미지에서 참조하고 있는 영역을 나타낸다고 보면 될 것 같습니다.
아키텍처는 (Conv x $l$) - GAP - Softmax 로 구성되어 있으며, NIN 및 GoogLeNet과 유사한 네트워크 구조 입니다.

Fig 2는 본 논문에서 제안하는 아키텍처 입니다. 마지막 합성곱 계층의 feature map들에 대해 GAP를 수행합니다. GAP를 수행하면 하나의 feature map당 하나의 scalar value가 나오게 됩니다. 이 값은 대응되는 feature map의 모든 값의 평균(=대표 값)입니다. 이후, 이를 가중 합산(weighted sum)과 softmax를 통해 클래스를 결정합니다. FC layer의 가중치는 각각의 feature map이 class prediction에 영향을 미치는 정도를 나타냅니다. 따라서, 가중치와 feature map의 element-wise 곱과 합을 통해 최종적인 CAM을 만들 수 있습니다.
먼저, Class를 계산하기 위한 단계입니다.
$f_k(x,y)$는 마지막 합성곱 계층(convolutional layer)의 유닛 $k$가 $(x,y)$에서 활성화된 값을 나타냅니다. 그런 다음, 유닛 $k$에 대해 GAP를 수행한 결과인 $F_k$는 아래와 같이 계산됩니다.
$$F_k = \sum_{x,y} f_k(x,y)$$
따라서, 주어진 클래스 $c$에 대해 소프트맥스의 입력 $S_c$ 다음과 같이 정의됩니다.
$$S_c = \sum_k w^c_kF_k$$
$w^c_k$는 유닛 $k$에 대해 클래스 $c$가 관련된 가중치를 나타냅니다. 즉, $w^c_k$는 $F_k$가 클래스 $c$에 얼마나 영향을 미치는지를 나타냅니다. 마지막으로, 클래스 $c$에 대한 소프트맥스 출력값 $P_c$ 는 다음과 같이 계산됩니다.
$$P_c = \frac{exp(S_c)}{\sum_c exp(S_c)}$$
다음은 CAM을 만드는 방법입니다. $F_k=\sum_{x,y}f_k(x,y)$를 클래스 점수 $S_c$에 대입하면 다음과 같은 결과를 얻습니다.
$$S_c = \sum_k w^c_k \sum_{x,y} f_k(x,y) = \sum_{x,y}\sum_k w^c_kf_k(x,y)$$
클래스 c에 대한 클래스 활성화 맵(CAM)을 $M_c$라고 정의하며, 각 공간적 요소는 아래와 같이 나타낼 수 있습니다.
$$M_c(x,y) = \sum_k w^c_kf_k(x,y)$$
따라서,
$$S_c=\sum_{x,y}M_c(x,y)$$
$M_c(x,y)$는 이미지가 클래스 $c$로 분류되도록 하는 공간 격자 $(x,y)$에서의 활성화 중요도를 직접적으로 나타냅니다.

Fig 3은 위의 방법을 사용해 생성된 CAM의 예시를 보여줍니다. 이를 통해, 여러 클래스에 대한 이미지의 판별적 영역이 강조되는 것을 확인할 수 있습니다. briard 클래스에서는 동물의 머리가, barbell 클래스에서는 역기의 원판이 강조되고 있습니다.

Fig 4는 동일한 이미지에 대해 서로 다른 클래스 $c$를 사용해 생성된 CAM의 차이를 나타냅니다. 이를 통해, 서로 다른 카테고리에 대해 판별적 영역이 동일 이미지에서도 다르게 나타남을 확인할 수 있습니다.
GAP vs GMP(Global Max Pooling)
이 논문에서는 GMP와 GAP간의 직관적인 차이를 강조합니다. GAP에서는 맵의 평균값을 계산할 때, 객체의 모든 판별적 부분을 식별해야 값을 최대화할 수 있습니다. 반면에, 낮은 활성화 값은 출력값을 감소시키기 때문에 전체적인 판별적 부분을 모두 찾는 것이 중요합니다.
반면 GMP에서는 가장 판별적인 부분(the most discriminative part) 하나의 점수만 고려되므로, 다른 이미지 영역의 낮은 점수는 최종 결과에 영향을 미치지 않습니다.
4. Experiments
이 절에서는 ILSVRC 2014 벤치마크 데이터셋을 사용하여 CAM의 객체 지역화 능력을 평가합니다.
4.1 Setup
AlexNet, VGGnet, GoogLeNet과 같은 널리 사용되는 CNN에서 CAM을 적용했을 때의 효과를 평가합니다. 일반적으로, 각 네트워크에서 최종 출력 계층 이전의 FC layer를 제거하고, 이를 GAP 계층과 softmax 계층으로 대체했습니다. (FC layer를 제거하면 네트워크 파라미터 수가 크게 줄어듭니다. VGG의 경우 90% 이상 감소합니다. 하지만 분류 성능에는 일부 감소가 발생합니다.)
객체 지역화 성능 향상을 위해 GAP 이전의 마지막 합성곱 계층이 더 높은 공간 해상도를 갖도록 설정합니다. 각 CNN에서 일부 계층을 제거하여, 13x13 또는 14x14의 feature map 해상도를 만듭니다. 이후, 3x3 크기의 필터, 스트라이드 1, 패딩 1, 임베딩 차원 1024의 합성곱 계층을 추가한 후, GAP 계층과 softmax 계층을 추가했습니다.
분류와 지역화 모두 ILSVRC의 error metric인 top-1과 top-5 error를 사용합니다.
4.2 Object Classification
우선, 분류 성능을 비교합니다. 기존 original CNN 모델과, fc 레이어를 제거하고 GAP, softmax 계층을 추가한 모델간의 top-1, top-5 error 비교입니다. 대부분 fc 레이어를 제거했을 때 1~2% 정도의 성능 저하가 발생합니다. 특히, AlexNet에서 성능 저하가 크게 일어나며, 이를 보완하기 위해 GAP 이전에 두 개의 합성곱 계층을 추가하여 AlexNet*-GAP 네트워크를 구성했습니다. 그 결과, 기존 AlexNet과 비슷한 성능을 보이는 것을 확인합니다.
따라서, 전반적으로 GAP 네트워크에서도 분류 성능이 대부분 유지됨을 확인했습니다.

네트워크가 분류에서 좋은 성능을 보여야 객체 지역화에서도 높은 성능을 달성할 수 있습니다. 왜냐하면, 객체 지역화는 객체의 카테고리(object category)와 바운딩 박스 위치(bounding box location)을 모두 정확하게 식별해야 하기 때문입니다.
4.3 Object Localization
객체 지역화를 수행하기 위해서는 바운딩 박스와 객체 카테고리를 생성해야 합니다. CAM에서 바운딩 박스를 생성하기 위해, 임계값을 설정하여 히트맵을 분할합니다. 먼저, CAM 값이 최대값의 20% 이상인 영역을 분할합니다. 그런 다음, segmentation map에서 가장 큰 연결 성분을 포함하는 바운딩 박스를 선택합니다.
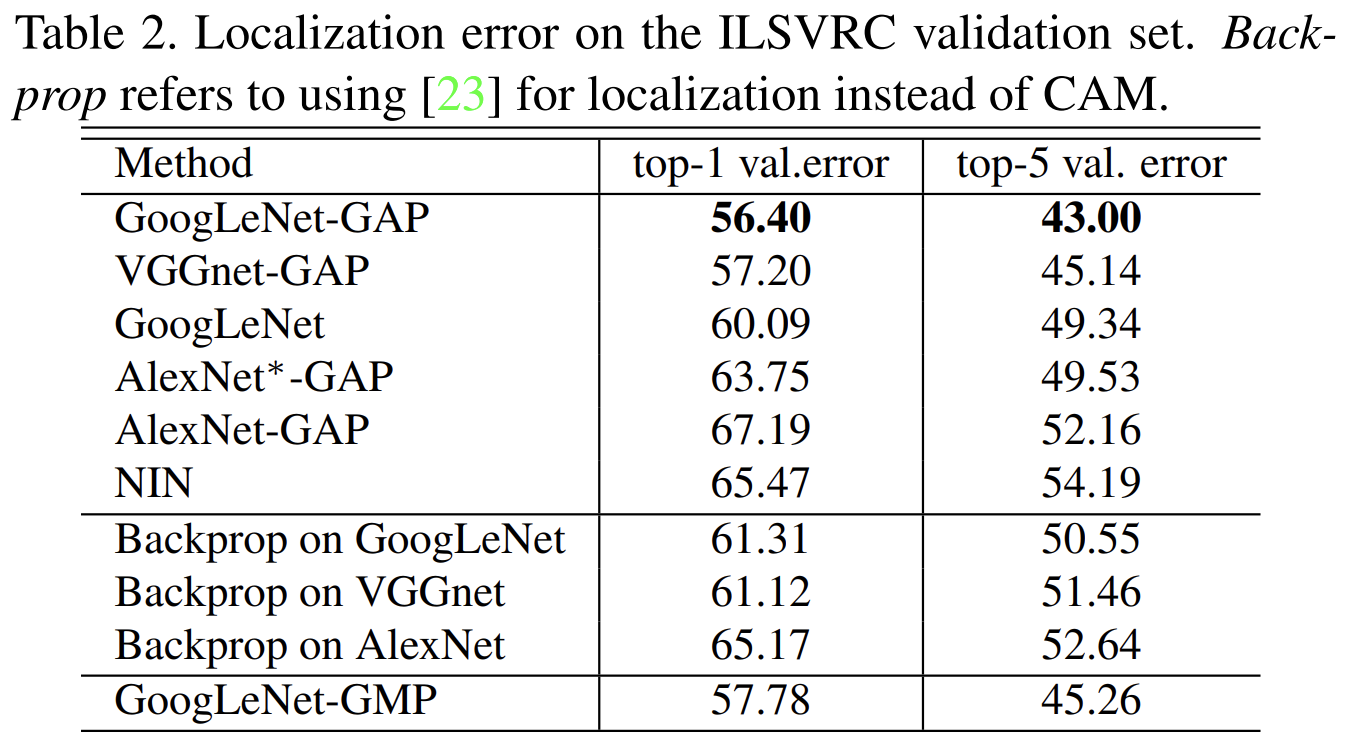
실험 결과, GAP 네트워크가 모든 baseline 접근법 보다 더 나은 성능을 보였음을 확인합니다. 특히, GoogLeNet-GAP은 가장 낮은 오류율을 기록합니다. 단 하나의 주석된 바운딩 박스도 사용하지 않고 훈련된 네트워크라는 점에서 매우 훌륭한 결과라고 할 수 있습니다.

Fig 5는 CNN-GAP, CNN, backpropagation method 간의 class activation map을 시각화하여 비교합니다.

Fig 6은 위 방법을 사용해 생성된 바운딩 박스의 예시입니다. a)는 GoogleNet-GAP의 localization 예시, b)는 GoogleNet-GAP(위 두개)과 backpropagation 방법을 사용한 AlexNet(아래 두개)의 예시를 비교한 결과입니다. 빨간색 박스는 예측된 박스를, 초록색 박스는 ground-truth 박스를 나타냅니다. CNN-GAP 방법이 backpropagation 방법보다 box 위치를 더 잘 찾은 것 같습니다.

Table 3는 weakly-supervised 방식과 fully-supervised 방식을 비교한 결과 테이블입니다. weakly-supervised 는 네트워크가 학습하고자 하는 직접적인 annotation인 bounding box location 없이, image-class(label) 단위로 학습한 뒤, bbox location을 평가하는 것을 말합니다. fully-supervised는 image-bbox 단위의 직접적인 학습을 말합니다.
GoogLeNet-GAP은 휴리스틱한 방법을 적용했을 때 top-5 error가 37.1%로 fully-supervised의 AlexNet이 34.2%의 오류율을 보인 것과 근접한 결과입니다.
Heuristics?
인간의 직관을 반영하는 사고방식을 뜻함.
여기서는 GoogLeNet-GAP의 localization 성능을 올리기 위해 실험적 경험/직관을 하이퍼파라미터로 사용함.
GoogLeNet-GAP (heuristics)
- 1위와 2위 예측 클래스에서는 각각 tight한 바운딩 박스와 losse한 바운딩 박스를 선택
- 3위 예측 클래스에서는 loose 바운딩 박스 하나를 선택
이는 분류 정확도와 지역화 정확도 간의 trade-off를 고려한 것
하지만, 동일한 네트워크 구조를 사용했을 때, weakly-supervised 기반 GoogLeNet-GAP와 fully-supervised 기반 GoogleNet을 비교하면 여전히 성능 격차가 존재합니다. 이는 여전히 개선할 여지가 남아 있습니다.
4.4 Fine-grained Recognition
이 절에서는 바운딩 박스 주석이 있는 CUB-200-2011 데이터셋을 통해 지역화 능력을 측정합니다.

GoogLeNet-GAP이 기존 접근법들과 비슷한 성능을 보였음을 확인했으며, 바운딩 박스 주석을 사용하지 않고 이미지 전체를 사용했을 때 63.0%의 정확도를 달성합니다. 바운딩 박스 주석을 사용했을 때에는 70.5%로 향상됩니다.
바운딩 박스를 식별한 뒤, 바운딩 박스 내의 크롭(crop)된 이미지에서 다시 특징을 추출하여 훈련과 테스트를 수행합니다. 이 접근을 통해 성능이 67.8%로 상당히 향상됨을 확인합니다. 지역화 능력은 fine-grained recognition에 있어 특히 중요합니다. 세부 카테고리 간의 차이가 미묘하기 때문에, 더 집중된 이미지 크롭을 통해 더 나은 지역적 판별이 가능하기 때문입니다.

Fig 7은 CUB200 데이터셋의 새(bird) 카테고리에 속하는 일부 이미지에서 생성된 CAM과 추론된 바운딩 박스(빨간색)를 보여줍니다. IOU 0.5 기준에서 41.0%의 정확도를 달성했습니다.
4.5 Pattern Discovery
이 절에서는 CAM이 객체를 넘어, 이미지에서 공통 요소나 패턴을 식별할 수 있는지 탐구합니다. 예를 들어, 텍스트나 고차원 개념(high-level concepts)를 인식할 수 있는지 확인합니다.
Discovering informative objects in the scenes:
SNU 데이터셋에서 10개 장면 카테고리(scene categories)를 선택합니다. 각 카테고리는 최소 200개 이상의 주석된 이미지이며, 총 4,675개의 이미지를 사용합니다. 각 장면 카테고리에 대해 One-vs-All 방식의 linear SVM을 학습하고, 해당 SVM 가중치를 사용하여 CAM을 계산합니다.

Fig 9에서는 예측된 장면 카테고리에 대해 생성된 CAM과 함께, 각 장면 카테고리에서 자주 등장하는 상위 6개의 객체 목록과 함께 객체의 등장 빈도를 표시했습니다.
이를 통해, 단순히 장면(scene)을 분류하는 것 뿐만 아니라, 장면을 대표하는 중요한 객체를 감지할 수 있음을 보입니다.
Concept localization in weakly labeled images:
Hard-Negative Mining 알고리즘을 사용하여 concept detector를 학습하고, 이를 통해 이미지에서 concept을 지역화하기 위해 CAM을 적용했습니다.
짧은 문구에 대한 detector를 학습하기 위해 캡션에 포함된 이미지들로 구성된 양성 집합(positive set)과 관련 단어가 포함되지 않은 무작위로 선택된 이미지들로 구성된 음성 집합(negative set)으로 구성했습니다.

Fig 10은 두 concept detector에 대해 상위 순위 이미지(top ranked images)와 CAM을 시각화했습니다.
이를 통해 CAM이 concept에 대한 유의미한 영역을 정확히 지역화하는 것을 확인했습니다. 이는 해당 문구가 일반적인 객체 이름보다 훨씬 추상적임에도 불구하고 이루어진 결과입니다.
Weakly supervised text detector:
SVT 데이터셋에서 텍스트가 포함된 350개의 Google StreetView 이미지를 양성 집합으로, SUN 데이터셋에서 무작위로 샘플링한 야외 장면 이미지를 음성 집합으로 사용하여 weakly supervised learning 기반으로 텍스트 탐지기를 학습했습니다.

Fig 11에서 볼 수 있듯이, 바운딩 박스 주석 없이도 텍스트 위치를 정확히 강조하는 결과를 보여줍니다.
Interpreting visual question answering:
VQA(Visual Question Answering)을 위해 base-line approaach에 논문의 접근법과 CAM을 적용한 실험입니다.

Fig 12에서 볼 수 있듯이, 논문의 접근법은 예측된 답변과 관련된 이미지 영역을 정확히 강조하는 결과를 볼 수 있습니다.
4.6 Visualizing Class-Specific Units
처음 Introduction에서 소개드린 Object Detectors Emerge In Deep Scene CNNs 논문은 CNN이 다양한 계층에 있는 convolutional units이 low-level (texture, material) 부터, high-level (object, scene) 과 같은 고수준 개념을 식별하는 visual concept detector로 작동한다고 말하고 있습니다. 하지만, 해당 논문은 fc layer를 사용하기 때문에 다른 카테고리를 식별하는 데 있어 특정 유닛의 중요성을 확인하기 어려운 문제가 있습니다.
이 논문에서는 fc layer 대신에 GAP와 softmax를 사용하여 특정 클래스에 대해 가장 판별적인 유닛을 직접 시각화 했습니다.

Fig 13의 상단은 객체 인식(object recognition), 하단은 장면 인식(scene recognition)으로 AlexNet*-GAP을 훈련한 결과입니다. 각 행은 각 유닛이 이미지의 어떤 부분을 가장 활성화 하고 있는지 시각적으로 확인할 수 있도록 분할된 이미지를 나타냅니다. 이를 통해 객체의 가장 판별적인 부분이 무엇인지, 해당 부분을 감지하는 유닛이 정확히 무엇인지 확인할 수 있습니다.
예를 들어, 강아지 얼굴과 몸의 털을 감지하는 유닛은 Lakeland Terrier 분류에서 중요합니다. 소파, 테이블, 벽난로를 감지하는 유닛은 거실 분류에서 중요합니다.
이는 CNN이 일종의 bag of words를 학습한다고 추론할 수 있습니다. 여기서 각 단어는 특정 클래스와 관련된 판별적인 유닛을 의미합니다. 이러한 클래스별 유닛의 조합이 CNN이 이미지를 분류하는데 지침(guidance) 역할을 한다고 합니다.
5. Conclusion
이 연구에서는 CAM이라는 일반적인 기법을 제안합니다. 이 기법은 GAP가 적용된 CNN에 사용되며, 바운딩 박스 주석 없이도 객체 지역화를 수행할 수 있도록 합니다.
ILSVRC 벤치마크에서 weakly-supervised 기반 객체 지역화 작업에 대해 평가하였으며, GAP기반 CNN이 정확한 객체 지역화를 수행할 수 있음을 보입니다.
또한, CAM 지역화 기법이 다른 Visual recognition task에도 일반화될 수 있음을 보입니다. 즉, 논문에서 제안하는 기법은 일반적 지역화 가능 심층 특징(generic localizable deep features)을 생성하며, 이는 CNN이 각 task에서 사용하는 판별 기준(basis of discrimination)을 이해하는 데 도움을 줄 수 있습니다.
6. Limitation
CAM 구조의 한계점은 다음과 같습니다.
- 반드시 Global average pooling layer를 사용해야 합니다.
- CAM을 계산하기 위한 FC layaer의 weight를 구하기 위해 Fine-tuning이 필요합니다.
- 마지막 Convolutional layer의 feature map에 대해서만 CAM 을 추출할 수 있습니다.
이러한 한계점을 바탕으로 Grad-CAM이 등장하게 됩니다.