paper: ICCV 2017 Open Access Repository
code: xunhuang1995/AdaIN-style: Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization
0. Summary
이 논문에서는 실시간으로 임의의 스타일 변환을 가능하게 하는 간단하면서도 효과적인 접근법을 처음으로 제시합니다. 제안 방법의 핵심은 콘텐츠 특징의 평균(mean)과 분산(variance)을 스타일 특징의 평균과 분산에 맞추는 AdaIN 레이어 입니다.
1. Introduction

기존의 스타일 전이(style-transfer) 연구들에는 몇가지 제약이 있습니다. (1) 스타일 변화에 flexible 하지만 느린 방법, (2) 단일 스타일에 제한된 빠른 방법, (3) 스타일 변화에 flexible 하면서 중간 속도를 갖는 방법이 대표적입니다.
기존 연구들을 살펴보면, 스타일 변환에 대한 flexible과 속도 간의 트레이드 오프가 있는 것으로 보입니다. AdaIN은 스타일의 flexible과 속도의 장점을 모두 갖고 있는 방법라고 할 수 있겠습니다.
2. Related Work
2.1 Image style transfer using convolutional neural networks, CVPR, 2016

이 방법은 Tbl 1의 'Gatys et al' 이 제안한 방법입니다.
style transfer task에서 대표적인 논문인 것 같습니다. Gram matrix를 이용하여 Style Image의 텍스처와 패턴 정보를, Content loss를 이용하여 이미지의 구조를 유지하면서 Noise image를 iterative하게 반복하여 업데이트해나가는 방법입니다.
사전 학습된 VGG-19 네트워크를 Content Encoder와 Style Encoder로 사용하며, 이미지를 생성하기 위해 Decoder를 두지 않고, noise image로부터 pixel 방향으로 gradient를 흘려 pixel을 업데이트 하는 방법으로 이미지가 생성됩니다. 따라서, 어떤 style image와 content image가 들어오더라도 처리할 수 있습니다. 하지만, 반복적으로 forward-backward를 수행하며 noise image를 업데이트하기 때문에 시간이 오래걸린다는 단점이 있습니다.
2.2 Improed Texture Networks: Maximizing Quality and Diversity in Feed-forward Stylization and Texture Synthesis
이 방법은 Tbl 1의 'Ulyanov et al'이 제안한 방법입니다.
이 저자는 Instance Normalization을 최초로 제시한 분입니다. 기존에 사용하던 BN대신, IN을 적용하여 각 샘플별로 독립적으로 스타일 정보를 효과적으로 유지할 수 있었다고 합니다.
네트워크로는 Encoder-Decoder 구조를 사용하고, 특징 공간에서 스타일 변환을 수행한 후 디코더를 통해 다시 픽셀 공간으로 복원하는 구조를 사용합니다. 학습 과정에서 특정 스타일화된 이미지를 생성할 수 있도록 Decoder가 사전 학습됩니다.
따라서, 한번의 single-forward만으로 이미지를 생성할 수 있어서 빠르다는 장점이 있지만, style 변화에 flexble하지 않다는 단점이 있습니다.
3. Background
3.1 Batch Normalization
3.2 Instance Normalization
Batch 정규화와 Instance 정규화에 대한 설명은 이전에 정리한 포스트로 대신하겠습니다.
Batch/Layer/Group Normalization — 191
3.3 Conditional Instance Normalization
CIN(conditional Instance Normalization)은 파라미터 $\gamma$와 $\beta$를 학습하는 대신, 각 스타일 $s$에 대해 서로 다른 파라미터 $\gamma_s$와 $\beta_s$를 학습하는 정규화 방법입니다.
$$ CIN(x;s) = \gamma_r (\frac{x - \mu(x)}{sigma(x)}) + \beta_s $$
학습 중에는 스타일 이미지와 그 인덱스 $s$가 고정된 스타일 집합 $s$ $\in$ ${1,2,..,S}$ 에서 무작위로 선택됩니다. 그런 다음, 콘텐츠 이미지는 CIN 레이어에서 해당 $\gamma_s$와 $\beta_s$를 사용하는 스타일 변환 네트워크를 통해 처리됩니다.
4. Interpreting Instance Normalization
(conditional) instance normalization의 성공에도 불구하고, 이러한 normalization 방법들이 style-transfer에서 잘 작동하는 이유는 명확하지 않습니다.

IN이 style normalization에 효과적임을 증명하기 위해, 몇가지 실험을 진행합니다. Figure 1의 (a)는 original image, (b)는 contrast normalized images, (c)는 style normalized images에 대해 각각 BN과 IN의 style-transfer 에서 Style loss의 수렴 속도를 비교합니다.
실험 결과, Style normalized image에 대해서 IN과 BN의 수렴 속도 차이가 크게 줄어듭니다. 이를 통해, IN은 style normalization을 수행하는 것을 알 수 있다고 합니다.
5. Adaptive Instance Normalization
저자는 IN을 확장하여 AdaIN(Adaptive Instance Normalization)을 새롭게 제안합니다. AdaIN은 Content 입력 $x$와 스타일 입력 $y$를 받아, $x$의 채널별 평균과 분산을 $y$의 평균과 분산에 맞춥니다. AdaIN은 BN, IN, CIN과 달리 learnable Affine parameter($\gamma$, $\beta$)가 없습니다. 대신, style 입력으로부터 affine parameter를 adaptive하게 계산합니다.
$$AdaIN(x,y) = \sigma(y) (\frac{x-\mu(x)}{\sigma(x)}) + \mu(y)$$
이를 통해 정규화된 Content 입력을 $\sigma(y)$로 스케일링하고 $\mu(y)$로 이동시킵니다.
6. Experimental Setup
6.1 Architecture
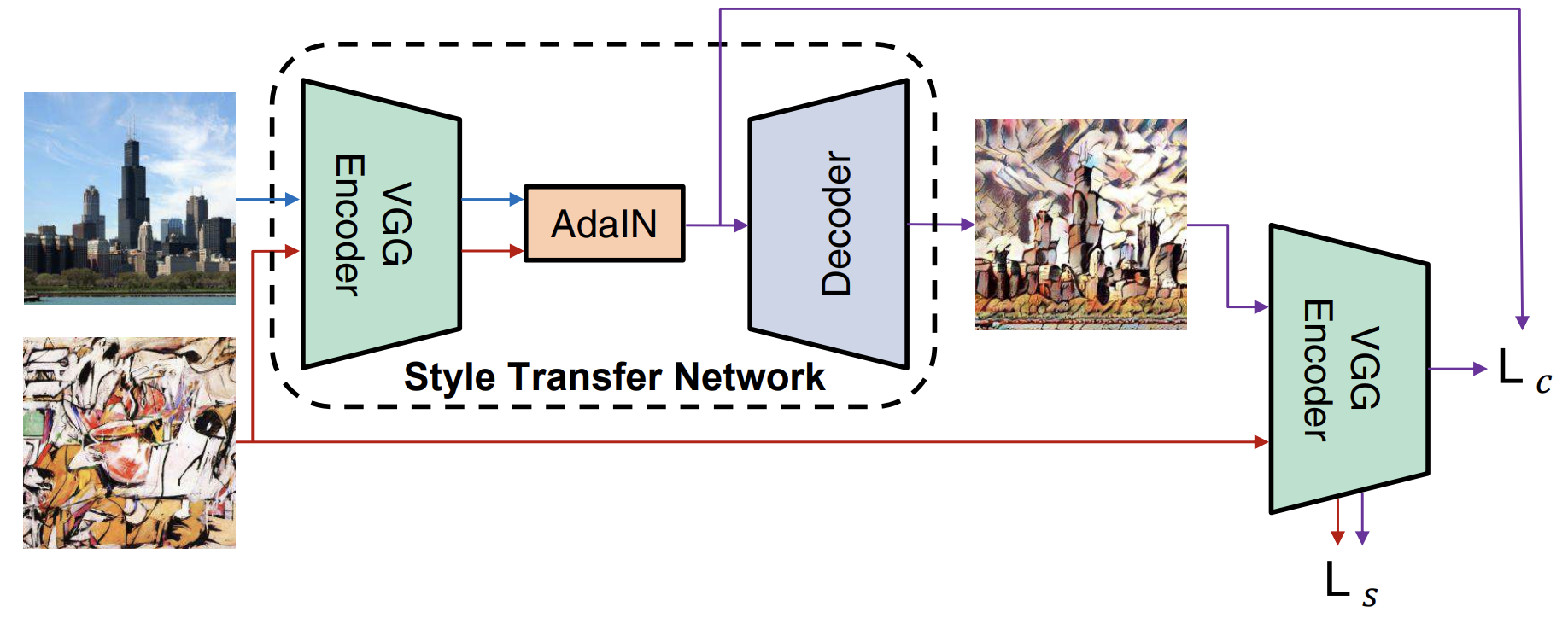
스타일 변환 네트워크 $T$ 는 콘텐츠 이미지 $c$와 임의의 스타일 이미지 $s$를 입력으로 받아, 콘텐츠 이미지의 콘텐츠와 스타일 이미지의 스타일을 결합한 이미지를 생성합니다.
간단한 인코더-디코더 아키텍처로 구성되어 있으며, 인코더 $f$는 사전 학습된 VGG-19 의 몇 개 계층(최대 relu4_1)로 고정됩니다.
다음 학습 과정에서 encoder는 고정(freeze)하고, decoder만을 학습합니다.
(1) 먼저, 콘텐츠 이미지와 스타일 이미지를 통해 각각의 특징 맵을 추출합니다. 이후, AdaIN 레이어를 통해 콘텐츠 특징 맵의 평균과 분산을 스타일 특징 맵의 평균과 분산에 맞춰줍니다. 이를 통해 target 특징 맵 $t$를 생성합니다.
$$t = AdaIN(f(c), f(s))$$
(2) 무작위로 초기화된 디코더 $g$는 $t$를 다시 이미지 공간으로 매핑하도록 학습되어 스타일화된 이미지 $T(c,s)$를 생성합니다.
$$T(c,s) = g(t)$$
6.2 Training
(1) 콘텐츠 손실 $L_c$는 target feature과 predicted image feature 간의 유클리드 거리로 계산합니다. $t$는 AdaIN의 출력입니다. $g(t)$를 통해 스타일 이미지의 스타일을 담고 있는 이미지를 생성했을 때, 이를 다시 Encoder를 통해 추출한 Feature map과의 L2 loss를 통해 Content를 유지하게 해줍니다.
$$L_c = || f(g(t)) - t ||^2$$
(2) 스타일 손실 $L_s$는 입력 스타일 이미지 $s$의 feature map과, AdaIN layer를 통해 스타일 전이된 feature map $t$ 로부터 복원된 이미지를 Encoder를 통해 추출한 feature map간의 평균과 분산에 대해 유클리드 거리를 계산합니다. 이를 통해, $g(t)$로부터 생성된 이미지가 입력 스타일 이미지의 스타일을 잘 담고 있게 해줍니다.
$$L_s = \sum^L_{i=1} || \mu(\phi_i(g(t))) - \mu(\phi_i(s)) ||^2 + \sum^L_{i=1}|| \sigma(\phi_i(g(t))) - \sigma(\phi_i(s)) ||^2$$
(3) 최종적으로는 콘텐츠 손실 $L_c$와 스타일 손실 $L_s$가 결합된 $L$을 사용합니다.
$$L = L_c + \lambda L_s$$
7. Results
7.1 Comparison with other methods
이 절에서는 다음 세 가지 style-transfer 방법과 AdaIN을 비교합니다.
- the flexible but slow optimization-based method
- the fast feed-forward method restricted to a single style
- the flexible patch-based method of medium speed

Qualitative Examples
Fig 4에서는 비교된 방법들이 생성한 스타일 변환 결과를 보여줍니다. 주목할 점은, Ulyanov 의 결과는 각 테스트 스타일에 맞게 하나의 네트워크를 학습하여 얻어진 것입니다. 그럼에도 불구하고, 본 논문의 방법으로 스타일화된 이미지 품질은 다른 방법들과 비교했을 때 경쟁력이 있다고 보여집니다.
Quantitative evaluations
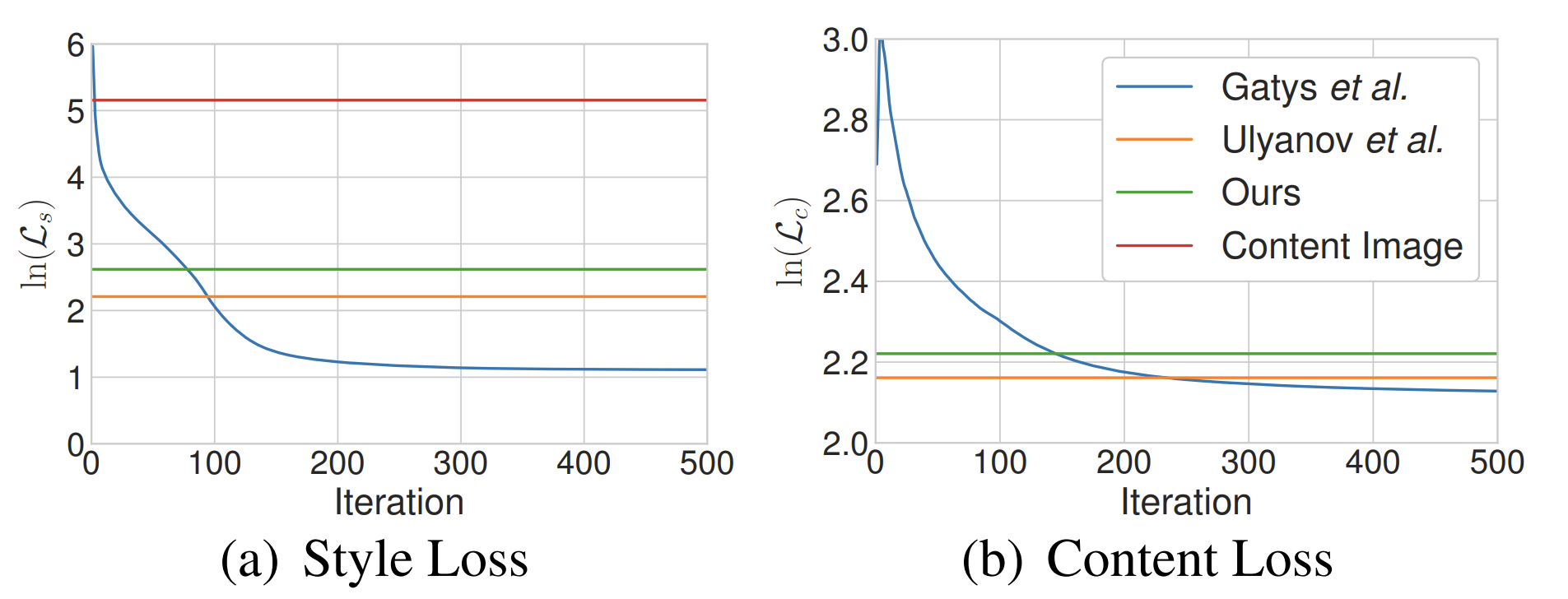
Flexible과 speed간의 관계를 살펴보기 위해, 각 방법들에 대해 Style loss와 Contet loss를 살펴봅니다. Ulyanov의 방법이 특정 테스트 스타일에 대해 개별적으로 훈련되었음을 감안하면, 꽤 좋은 성능을 보여주고 있습니다.
Speed analysis
이 절에서는 style transfer image 생성에 걸리는 시간을 비교합니다. 다른 방법들 대비 빠른 시간과 Style에 대해 flexible한 점을 확인할 수 있습니다.
7.2 Additional experiments
이 절에서는 제안된 아키텍처 선택을 정당화하기 위한 추가 실험이 제시됩니다. Sec. 6 에서 제안된 기본 아키텍처 구조를 Enc-AdaIN-Dec 라 명명합니다.
(1) Enc-Concat-Dec
(2) Enc-AdaIN-BNDec
(3) Enc-AdaIN-INDec
에 대해서 추가적인 실험과 정성/정량적인 비교를 제시합니다.

Figure 5 을 확인해보면, (d)는 콘텐츠 손실을 줄이는 데 실패합니다. (e)와 (f) 또한 더 나쁜 결과를 보이고 있습니다.

Figure 6 은 각 방법들에 대한 Loss를 제시합니다. Enc-Concat-Dec 같은 경우, Content loss를 줄이지 못하고, BNDec, INDec 을 사용하는 경우, 사용하지 않는 경우에 비해 Style loss와 Content loss가 모두 증가함을 알 수 있습니다.
7.3 Runtime controls
이 절에서는 유연성을 강조하기 위해 스타일 변환 네트워크가 사용자들에게 추가적인 제어를 제공함을 보여줍니다.
Content-Style Trade-Off

네트워크는 $\alpha=0$일 때 콘텐츠 이미지를 충실히 복원하려 하고, $\alpha=1$ 일 때 가장 스타일화된 이미지를 합성하려고 합니다. Fig. 7에서 $\alpha$를 0에서 1로 변경하면 콘텐츠 유사성에서 스타일 유사성으로의 부드러운 전환을 관찰할 수 있습니다.
$$T(c, s, \alpha) = g((1-\alpha)f(c) + \alpha AdaIN(f(c),f(s)))$$
Style Interpolation

K개의 스타일 이미지 $s_1,s_2,...,s_k$와 해당 가중치 $w_1, w_2, ..., w_k$가 주어졌을 때, 다음과 같이 특징 맵을 보간하여 스타일을 보간할 수 있습니다. (fig. 8 참고)
$$T(c, s_{1,2,...k}, w_{1,2,...k}) = g(\sum^k_{k=1}w_k AdaIN(f(c),f(s_k)))$$
Spatial and Color Control
이 절에서는 스타일 변환의 색상 정보와 공간적 위치를 제어하는 제어 방식을 프레임워크에 통합한 결과를 보여줍니다.

콘텐츠 이미지의 색상을 유지하기 위해, 스타일 이미지의 색상 분포를 콘텐츠 이미지의 색상 분포에 맞춘 다음, color-aligned style image를 style input으로 사용합니다. 결과는 Fig 9과 같습니다.

Fig 10.에서는 콘텐츠 이미지의 서로 다른 영역을 서로 다른 스타일로 변환할 수 있음을 보여줍니다.
8. Discussion and Conclusion
style transfer를 위한 기존 접근법들은 픽셀을 gradient를 통해 업데이트 하거나, feed-forward network를 통해 업데이트 하는 방법을 채택했습니다. 그러나, 본 논문에서는 feature map 단위에서 style 을 transfer한 뒤, 이를 픽셀 공간으로 되돌리는 방법을 채택합니다.