Stanford에서 강의하는 CS231n에 대해서 공부하고 정리한 글입니다.
Slide: cs231n_2017_lecture10.pdf
Recurrent Neural Networks

Machine Learning의 관점에서 생각해보면, 모델이 다양한 입력을 처리할 수 있도록 유연해질 필요가 있다.
이러한 관점에서 RNN(Recurrent Neural Network)는 다양한 입/출력을 다룰 수 있는 장점이 있다.
RNN에는 one to one, one to many, many to one, many to many 의 여러 입/출력을 다룰 수 있는 네트워크들이 존재한다.
one to many는 Image Captioning과 같이, 입력이 이미지이고, 출력이 Sequence of words일 때 유용하다.
many to one은 Sentiment Classification과 같이, 입력이 Sequence of words 이고, 출력이 감정 데이터인 하나의 Sentiment일 때 유용하다.
many to many는 입/출력이 seq of words인 기계 번역, 입/출력이 영상인 Video Classification Task 등에 유용하다.

일반적으로 RNN은 Recurrent Core Cell을 가지고 있다.
그럼, 이 Cell에서는 다음과 같은 일들이 일어난다.
- RNN이 입력을 받는다.
- "Hidden State"를 업데이트 한다.
- 출력 값을 내보낸다.

조금 더 이해하기 쉽게 수식으로 풀어보자.
Cell의 $h_t$는 입력 $x_t$와 이전 셀의 $h_{t-1}$로 부터 구할 수 있다.
이는 $h_t = tanh(W_{hh}h_{t-1} + W_{xh}x_t)$ 로 표현할 수 있다.
출력 $y_t$는 $h_t$를 입력으로 하는 FC-layer를 통해 구할 수 있다.
이는 $y_t = W_{hy}h_t$ 로 표현할 수 있다.

전체적인 흐름을 보기 위해 Computational Graph를 살펴보자.
초기화된 hidden state $h_0$과 입력 $x_1$을 통해 다음 hidden state $h_1$를 구한다.

이 과정은 계속해서 반복된다.

이 때, hidden state를 update하기 위한 가중치 행렬 $W$는 매번 동일한 가중치 행렬이다.
$h$와 $x$는 매번 달라지지만, $w$는 동일하다.
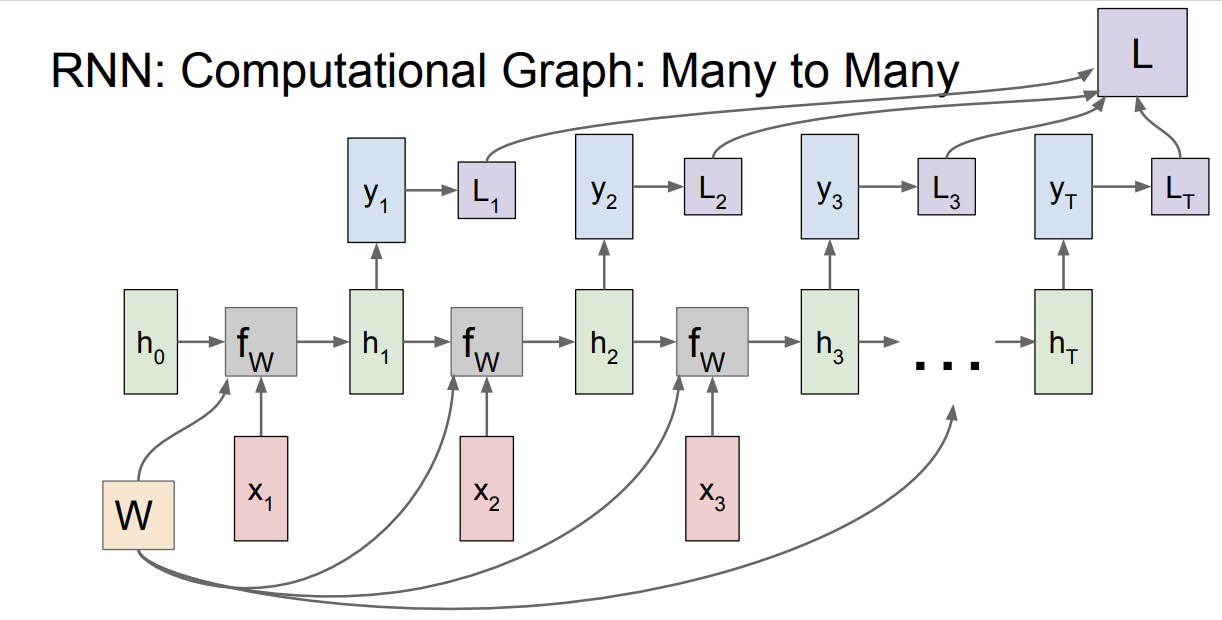
RNN Cell의 출력 $h_t$가 또 다른 네트워크에 들어가 $y_t$를 만들어 낸다.
many to many 의 관점에서, 각 스텝마다 개별적으로 $y_t$에 대한 Loss를 계산할 수 있고, 최종 Loss는 개별 loss들의 합이다.
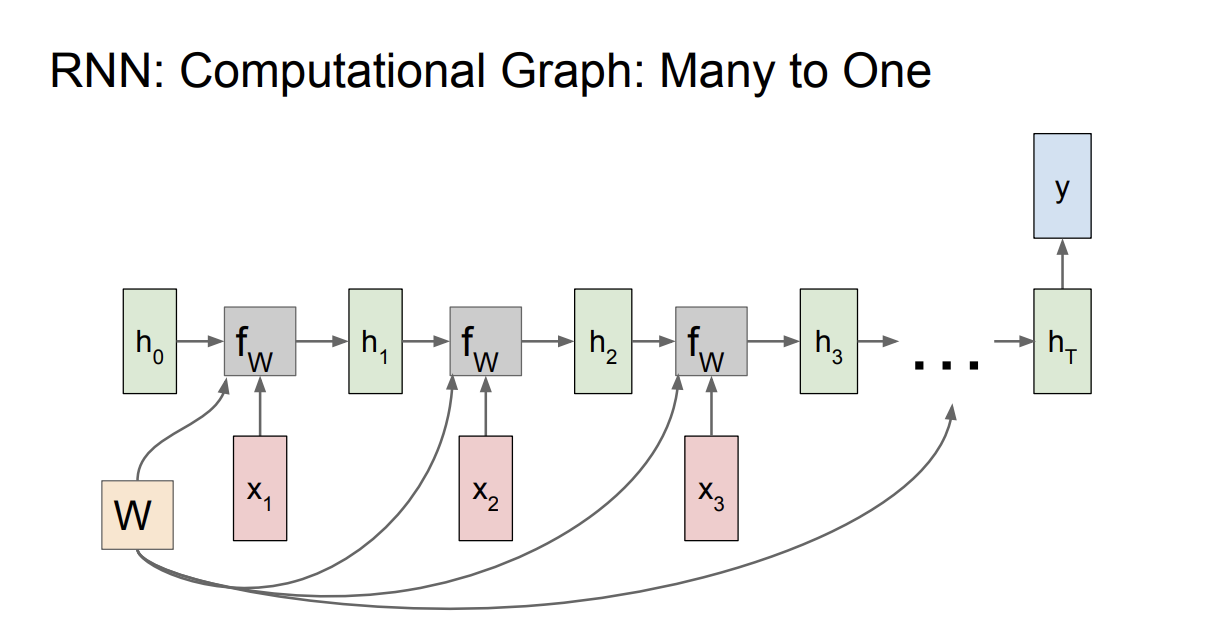
Many to one의 관점에선, 최종 hidden state에서만 결과 $y$가 출력되고, 이것에 대한 Loss가 최종 Loss가 된다.
One to Many도 쉽게 생각해 볼 수 있다.

Sequence to Sequence 모델에 대해서 알아보자.
이는 Machine translation에 사용될 수 있는 모델이며, 가변 입력과 가변 출력을 가지는 모델이다.
우리는 이 모델을 "many to one"과 "one to many"의 결합된 아키텍처로 볼 수 있다.
가변 입력을 받아 sentence를 요약하는 Encoder 구조와 이를 다시 sentence로 출력하는 Decoder 구조의 결합으로 생각해볼 수 있다.
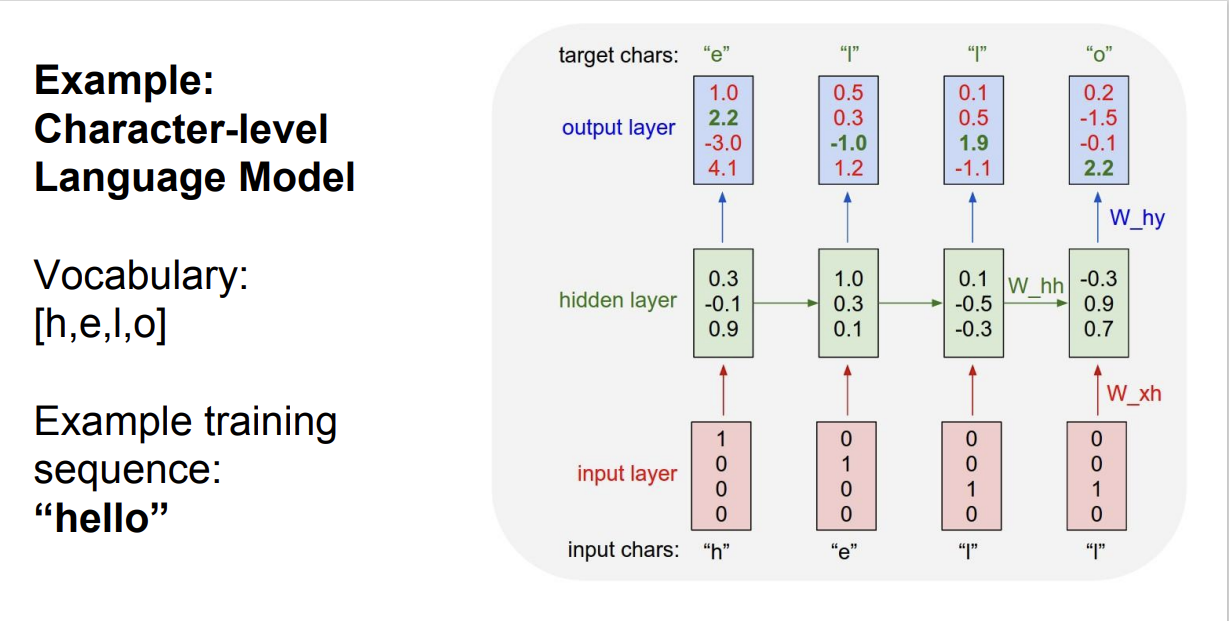
간단한 character level language model을 살펴보자.
네트워크는 문자열 시퀀스를 읽어, 현재 문맥에서 다음 문자를 예측해야 한다.
이 예제에서는 간단하게 [h, e, l, o] 문자만 있고, 학습시킬 문장은 "h, e, l, l, o" 이다.
Train time에서는 "hello"의 각 단어를 입력으로 넣어준다.
"hello"의 각 문자가 RNN의 $x_t$인 셈이다.
일반적으로, 문자를 입력으로 넣어주는 방법이 있다.
우리는 [h, e, l, o] 총 4개의 문자를 사용한다.
해당 글자 위치만 1로 표시하여 각 글자를 하나의 벡터로 표현한다.
가령, h를 벡터로 표현하는 경우는 [1, 0, 0, 0] 이고, 4-dimensional 벡터로 표현할 수 있다.
첫 스텝에서는, 입력 문자 'h'가 들어온다.
첫 번째 RNN cell로는 'h'가 들어가고, RNN cell 내부의 연산을 통해 $y_1$이 출력된다.
이 예제에서는 h 의 입력에서 e가 출력되어야 정답이다.
하지만, 첫번째 cell의 softmax를 살펴보면, o의 score가 가장 높다. 잘못 예측한 경우이고, softmax loss가 높게 측정될 것이다.
이 과정을 반복하여, 문장을 학습한다.
결국 이 모델은 문장의 문맥을 참고해서 다음 문자가 무엇일지를 학습하는 것이다.

모델의 Test time을 살펴보자.
모델에게 문장의 첫 글자만 준다. 이 경우 'h'가 된다.
RNN의 $x_1$은 'h' 이며, [1, 0, 0, 0]이 된다.
출력에서는 O에 대한 score(84%)가 가장 높은데, e가 출력 되었다.
Test time에서는 가장 높은 스코어를 선택하지 않고, 확률분포에서 샘플링한 값을 출력한다.
확률 분포에서 샘플링하는 방법을 사용하여 모델에서의 다양성을 얻을 수 있기 때문이라고 한다.
(아마도, Sequence of words에는 같은 입력이 중복으로 발생한다. Tokenize 방법에 따라 다르긴 하겠지만, 같은 접두사, 접미사 같은 것들이 들어오면 항상 같은 출력을 뱉는 문제가 발생할 수 있기 때문에, 출력의 다양성을 높히기 위해 확률 분포에서 샘플링 하는 방법을 사용하는 것 같다.)
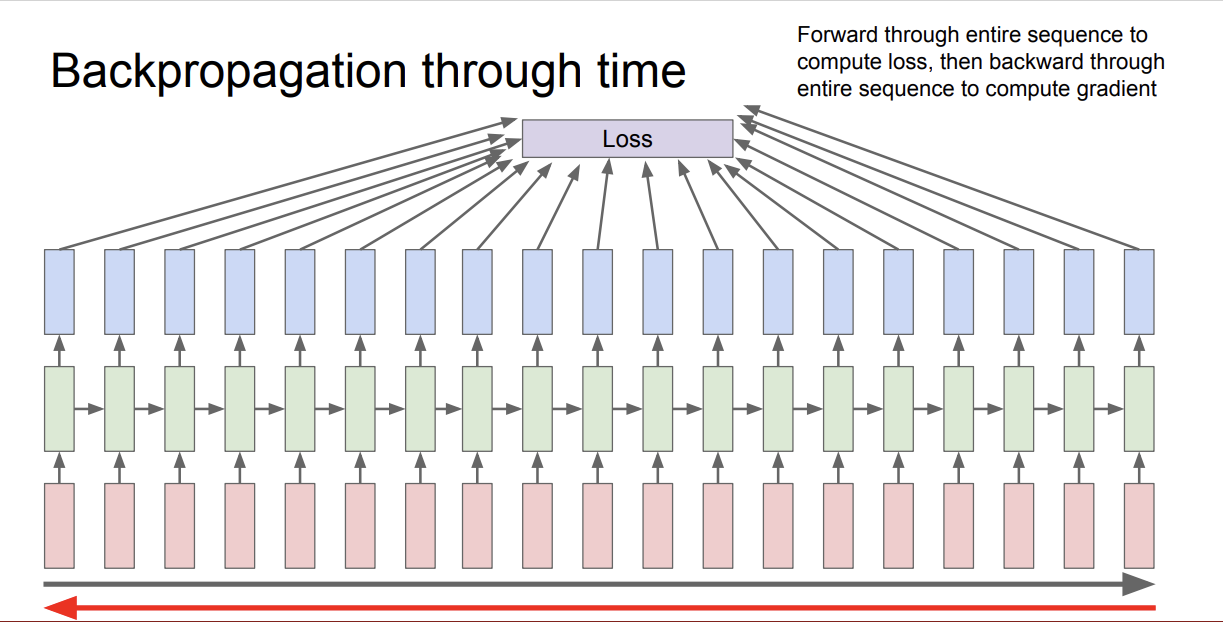
이 출력값들을 통해 모델의 Loss를 구할 수 있는데, 이를 backpropagation through time 이라고 한다.
forward pass가 전체 시퀀스에 대해 끝날 때 까지 출력이 생성되며, 시퀀스가 아주 긴 경우 문제가 될 수 있다.
Wikipedia 전체 문서로 학습 시킨다고 생각해보면, gradient를 계산하기 위해선 Wikipedia 전체 문서를 다 거쳐야 할 것이고,
문서 전체를 한번 거치고 나면 gradient update가 1회 수행된다.
이런 과정은 매우 느리고 모델이 수렴되기 힘들다. (메모리 사용량 또한 어마어마 할 것이다.)

대신, Truncated backpropagation 방법을 통해 backpropagation을 근사시키는 기법을 사용한다.
이 방법은 시퀀스가 엄청 길어서 무한대일 지라도 Train time에 한 스텝을 일정 단위로 잘라 이 서브시퀀스의 loss를 계산하여 gradient를 update하는 방법이다.
이 방법은 SGD 와 유사하다.
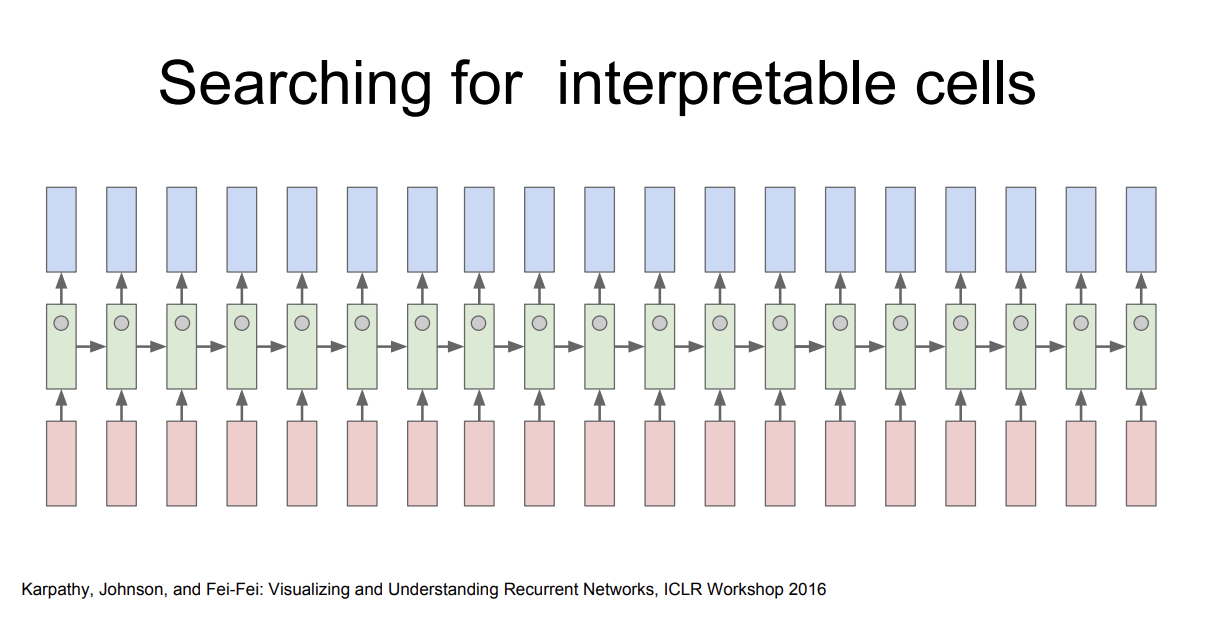
RNN에는 hidden state vector가 있고, 이 vector는 계속 업데이트 된다.
강의를 보면, 이 vector를 추출해보면 해석 가능한 의미있는 것들이 나올수도 있지 않을까 추측해 보았다고 하며 본인이 연구한 논문에 대해 소개하는데, 이 부분이 흥미롭다.
먼저, RNN을 특정 dataset으로 학습시키고, hidden vector를 하나 뽑아서 어떤 값들이 들어있는지 살펴보았다.
대부분의 hidden state는 아무 의미 없는 패턴이었다.

그런 다음, hidden state vector를 하나 뽑은 뒤, 그림에서의 시퀀스를 forward 시켜 보았다고 한다.
각 색깔은 시퀀스를 읽는 동안에 앞서 뽑은 hidden vector의 값을 의미한다고 한다.
RNN의 대부분의 cell은 다음에 어떤 문자가 와야할 지 알아내기 위한 low level language modeling 정도로밖에 보이지 않았다.
하지만 일부는 해석해볼만 하다.
빨간색은 -1, 파란색은 1을 의미한다.
hidden state가 $h_t = tanh(W_{hh}h_{t-1} + W_{xh}x_t)$ 임을 다시 생각해보자.
그럼, hidden state의 범위는 [-1, 1] 이며, 현재 Cell의 입력과 이전까지의 문맥($h_t$)를 통해 이 값이 정해지는 것을 알 수 있다.
그림에서의 예제를 살펴보자.
각 Cell들의 hidden state 값들을 각 Cell의 출력 $y_t$ 와 함께 시각화 한 것이다.
그림에서의 hidden state는 따옴표(quotes)를 찾는 벡터인것으로 추측해볼 수 있다.

줄 바꿈을 위해 현재 줄의 단어 갯수를 세는 듯한 cell 도 볼 수 있고

if문의 조건부를 찾는 Cell도 볼 수 있다.
굉장히 흥미롭다.
우리는 RNN을 통해 다음 문자를 예측하는 모델을 학습시켰을 뿐인데, 모델은 입력 데이터의 구조도 학습하게 되었다.
Reference
- Author blog, The Unreasonable Effectiveness of Recurrent Neural Networks
- (Paper) Visualizing and Understanding Recurrent Networks, [1506.02078] Visualizing and Understanding Recurrent Networks
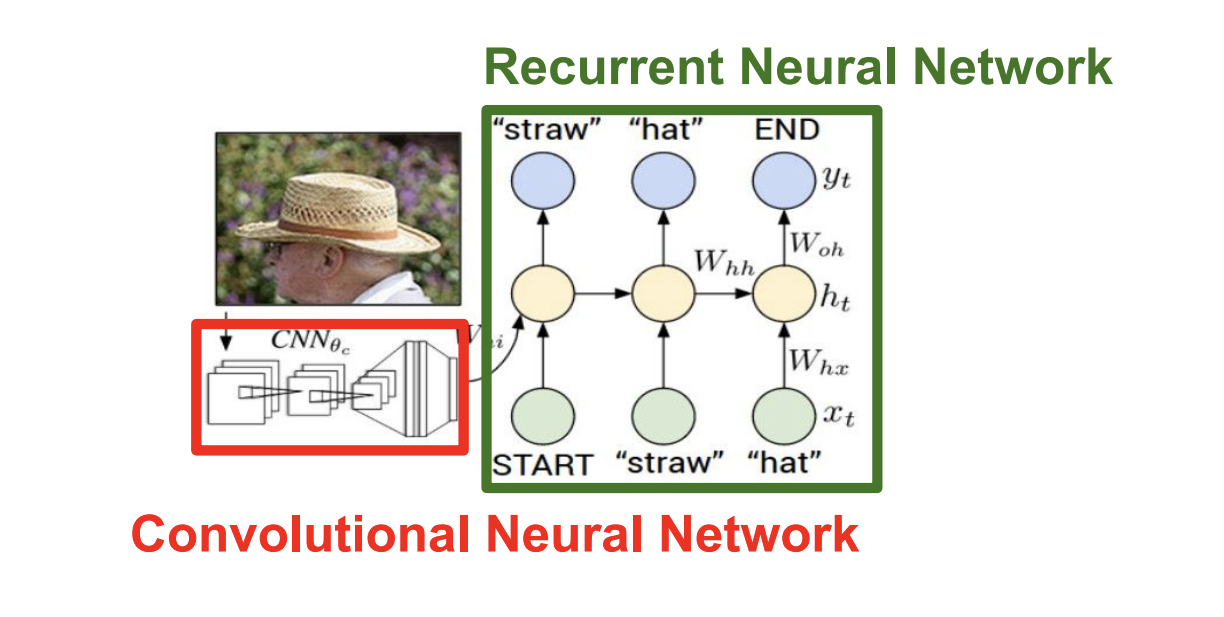
Computer Vision에 관련된 예시를 보자.
Image Captioning Model에 지금까지 배운 CNN과 RNN을 사용해볼 수 있다.
모델의 입력은 이미지 이고, 출력은 자연어 이다.

우선, 입력 이미지를 받아서 CNN의 입력으로 넣는다.
여기서 중요한 점은 Softmax score를 구하지 않고, 마지막 layer의 출력인 4096-dimensional vector를 RNN의 입력으로 사용하는 것이다.
이 vector는 이미지 정보를 잘 요약한 vector 가 된다.
우리는 이전에 RNN을 배울 때 입력 $x$와 이전 셀의 hidden state $h$를 가중합하여 다음 셀의 hidden state를 구했다.
이젠 이미지 정보인 $V$ 벡터 정보도 더해줘야 하므로, 다음과 같이 수식을 업데이트 한다.
$$h = tanh(W_{xh}x + W_{hh}h + W_{ih}v)$$
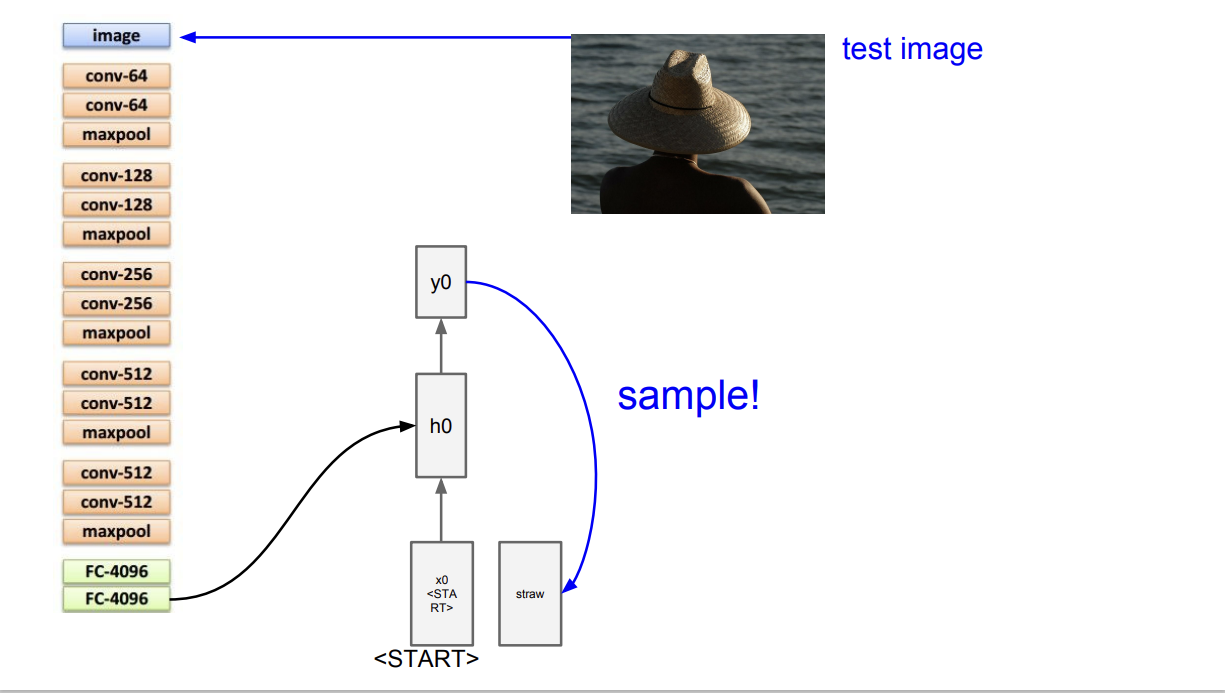
$h$를 통해 출력 분포 $y$를 계산하고, 이를 샘플링해 다음 스텝의 입력으로 넣어준다.

이렇게, <END> 토큰이 나올때 까지 과정을 반복하며, 모든 스텝이 종료되면 한 문장이 만들어진다.

이런 과정을 통해서 상당히 괜찮은 모델 결과를 뽑아볼 수 있다.

하지만, 이 모델도 다른 Machine learning 모델들 처럼 Train time에서 보지 못한 데이터에 대해서는 잘 동작하지는 않는다.

지금까지는 hidden state가 하나인 단일 RNN레이어를 살펴보았다.
실제로는 Multi-layer RNN을 많이 사용한다.
네트워크의 깊이가 깊어질 수록 성능이 좋아지는 법칙은 RNN에서도 적용된다.
그런데, RNN은 Backpropagation 과정에서 여러가지 문제가 발생한다.
해당 문제점에 관한 정리는 다른 포스트에 정리해두었습니다. (RNN: Backpropagation — 191)
이러한 문제를 완화하기 위해 LSTM이 제안된다.

LSTM에는 Cell당 두 개의 hidden state가 있다.
RNN과 유사한 개념인 $h$와 새로운 $c$ 라는 벡터가 있다.
두 벡터 모두 LSTM 내부에만 존재하며 밖으로 노출되지 않는 변수이다.
LSTM에는 4개의 gate가 있다.
I는 input gate이다. 입력 $x$에 대한 가중치이다.
F는 forget gate이다. F는 이전 스텝의 Cell 정보를 얼마나 망각(forget) 할지에 대한 가중치이다.
O는 output gate이다. $h$와 $c$에 대한 출력을 조절하는 가중치이다.
G는 gate gate이다. input cell을 얼마나 포함할지 결정하는 가중치이다.
I/F/O gate는 sigmoid를 사용한다. 값의 출력이 [0, 1] 이며,
G gate는 tanh를 사용한다. 값의 출력이 [-1, 1]이다.
$c_t$를 결정하는 수식을 살펴보자.
우선, [0, 1] 의 범위를 갖는 F gate를 통해 이전 $c_{t-1}$를 계속 기억할지 말지를 결정한다.
이후, I와 G gate의 element wise product인 i$*$g를 통해 각 요소를 증가시키거나 감소시킬 수 있다.
$h_{t}$는 $c_t$ 값이 $tanh$를 통과하여 O gate와 곱해진다.
$tanh$를 통과하여 그 값이 [-1, 1] 범위를 갖게 되고, O gate([0, 1] 범위)와 곱해져 출력 스케일을 결정 한다.
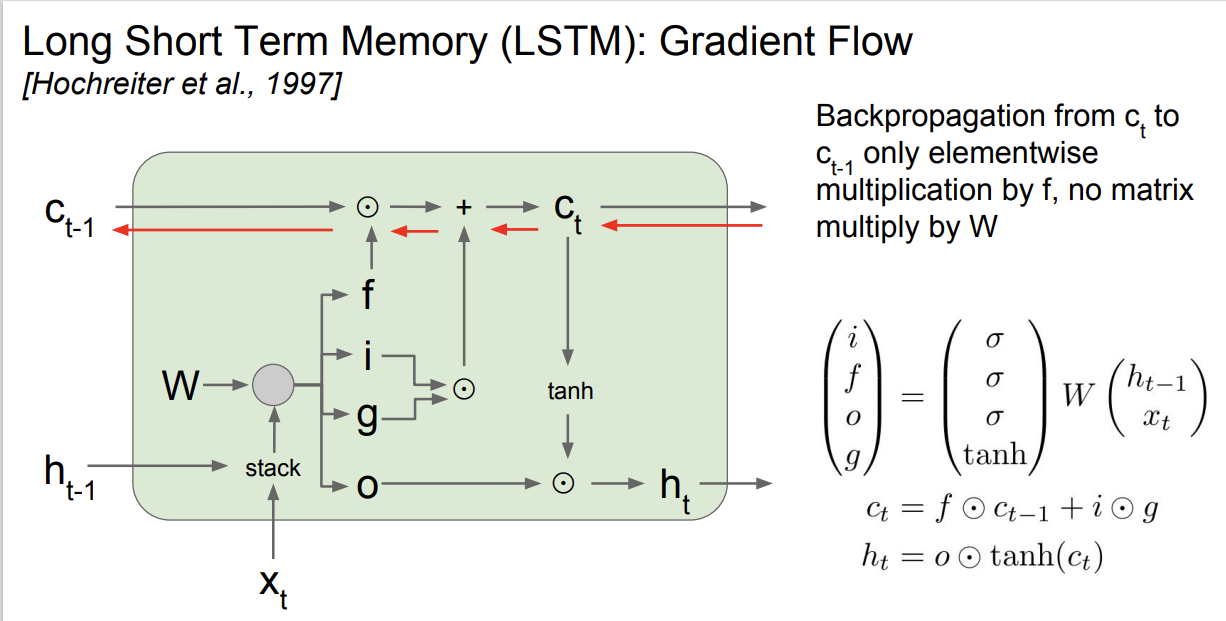
LSTM에서 Cell state의 Backpropagation을 살펴보자.
우선, Additional gate는 단순히 gradient가 양 갈래로 지나간다.
따라서, upstream gradient * element wise product(forget gate, $C_{t-1}$) 임을 알 수 있고,
이는 upstream gradient * forget gate 이다.
이것은 RNN에 비해 몇 가지 이점을 가져올 수 있다.
- forget gate와 곱해지는 연산이 matrix multiplication이 아닌, element-wise 방법이다.
- 매 스텝 다른 값의 forget gate와 곱해진다.
- RNN에서는 매 번 같은 가중치 행렬 $h_t$를 곱해 exploding/vanishing gradient 문제가 발생했다. 반면, LSTM에서는 스텝마다 변하는 forget gate를 곱하기 때문에 이 문제를 해결할 수 있다.
- LSTM에서는 backpropagation에서 $tanh$를 한 번만 거치면 된다.

결국, backpropagation에서 RNN에 비해 많은 이점을 가져올 수 있게 되었다.

이외에도, LSTM과 유사한 GRU(Gated Recurrent Unit)이 있다.
강의에서는 다 비슷비슷하며, 자세히 다루지는 않는다고 한다.
'Stanford CS231n' 카테고리의 다른 글
| Lecture 11: Detection and Segmentation (1) | 2024.11.26 |
|---|---|
| Weight Initialization (0) | 2024.11.11 |
| Lecture 9: CNN Architectures (1) | 2024.11.11 |
| Lecture 7: Training Neural Networks 2 (1) | 2024.11.08 |
| Lecture 6: Training Neural Networks 1 (2) | 2024.11.08 |